
今回はDeep Learningの適用分野のひとつである「超解像(英語:Super Resolution よくSRと省略される)」について、どのようなことをしているのかについてです。

1. 拡大と超解像
画像や動画の解像度をあげることを「超解像」と呼び、従来から使われている「アップコンバート」に近い処理です。例えば、元は100×100ピクセルの画像があるとして、これを例えば単純に150×150ピクセルにするだけでなら「リサイズ(拡大)」だが、拡大する際に元々存在しなかった画素を適切に補うことで被写体の鮮明度が上がる場合は「超解像」です。
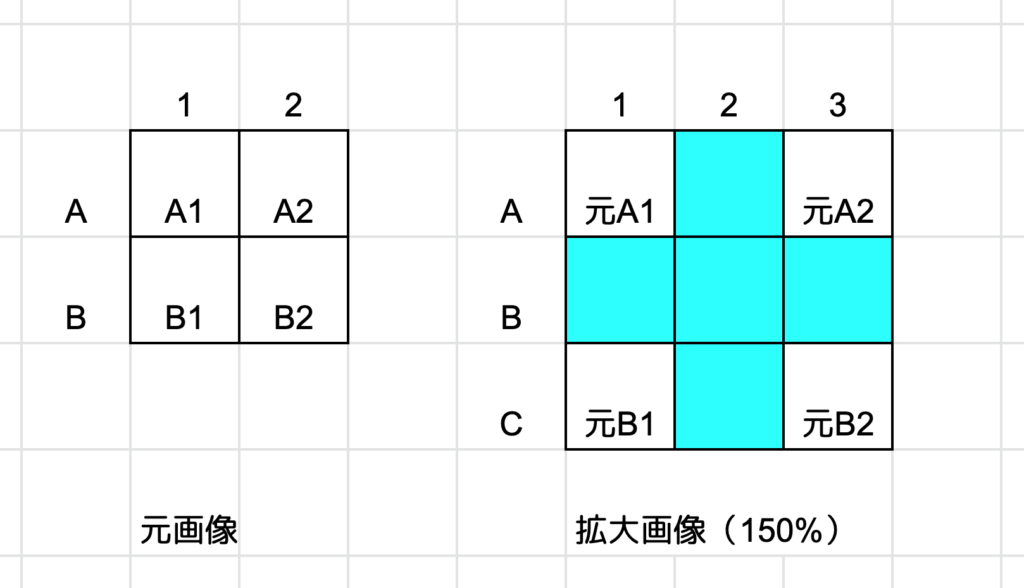
(上記、説明を簡潔にするため、若干不正確なことを意図的に書いています)
上記のように簡単のために「2×2ピクセル」の画像を「3×3ピクセル」の画像に拡大した際、本来の元画像では存在しなかった水色のピクセルをどのような色で補うかによって拡大された画像の鮮明度が異なります。
従来のDeep Learningを用いない補完方法では「補完されるべきピクセルの色は上下左右のピクセルの色の影響を受ける」という考え方のもとで数学的に決められていました。その数学的手法には「バイリニア法」「ニアレストネイバー法」「バイキュービック法」などがあり、それぞれについてメリットデメリットが語られてきました。しかし、上記の観点で欠けていたのは下記の視点でした。
- 1枚の画像の中にもバイリニア的な補完をすべき箇所とニアレストネイバー的な補完をすべき箇所が混在する
- 上記は「何のどの部分か」によって適切な補完アルゴリズムが異なる
この考えを包括する方向で画像の拡大(=超解像)を行うのがDeep Learningによる画像の拡大です。現時点で発表されているDeep Learningの超解像アルゴリズムは主に上記の1を網羅することに主眼をおいていて、「この画像のこのピクセルは、パンダの白黒の境目だからくっきりさせるべきだな」のような「被写体が何か」までは明示的に判別しないで補完パターンを学習しています。
2. 動画の超解像
単一の静止画像の超解像においては、その単一の画像内のピクセル属性が超解像結果の画像ピクセルの属性となることに尽きるのですが、動画の超解像についてはさらに発展したアルゴリズムが考案されています。
例えば、ドイツの研究者が考案した「TecoGAN」という動画超解像アルゴリズムがあるのですが、これは動画のNフレーム目の超解像を行ううえで(N-1)フレーム目と(N+1)フレーム目の同じ位置のピクセルの属性を考慮して行うものがあります。なお、通常の超解像処理ではニューラルネットワークへの入力テンソルは3次元のテンソルですが、TecoGANの場合は前後のフレームの画像も入力とするので厚みが3ある4次元テンソルとなります。このため、通常の超解像処理よりもメモリーを多く消費しますし、処理自体も重いです。
3. なんでも綺麗に超解像できるわけではない
実際に超解像していて「これは超解像しにくいな(綺麗に解像度が上がらない)」という画像・動画があります。それは「動きのある部分のボケ」です。このようなボケ方をした部分はDeep Learningでの超解像でも明瞭になりにくい。逆の言い方をすれば、撮影した時点のカメラのシャッタースピードまたはフレームレートが高速な状態で撮られた画像・動画であれば動きによるボケが少なく超解像しやすいですが、昔の消費者向けカメラで撮られたものなどは超解像しにくいです。
以上、ざっくり概要ですが超解像について書きました。ネットでは「waifu2x」などがダウンロードできますので、一度試して時間してみてください。